November 13th, I attended the USENIX Release Engineering Summit in Washington, DC. This summit was along side the larger LISA conference at the same venue. Thanks to Dinah McNutt, Gareth Bowles, Chris Cooper, Dan Tehranian and John O’Duinn for organizing.

I gave two talks at the summit. One was a long talk on how we have scaled our Android testing infrastructure on AWS, as well as a look back at how it evolved over the years.
 |
|
Picture by Tim Norris – Creative Commons Attribution-NonCommercial-NoDerivs 2.0 Generic (CC BY-NC-ND 2.0)
https://www.flickr.com/photos/tim_norris/2600844073/sizes/o/ |
I gave a second lightning talk in the afternoon on the problems we face with our large distributed continuous integration, build and release pipeline, and how we are working to address the issues. The theme of this talk was that managing a large distributed system is like being the caretaker for the water, or some days, the sewer system for a city. We are constantly looking system leaks and implementing system monitoring. And probably will have to replace it with something new while keeping the existing one running.
 |
| Picture by Korona Lacasse – Creative Commons 2.0 Attribution 2.0 Generic https://www.flickr.com/photos/korona4reel/14107877324/sizes/l |
In preparation for this talk, I did a lot of reading on complex systems design and designing for recovery from failure in distributed systems. In particular, I read Donatella Meadows‘ book Thinking in Systems. (Cate Huston reviewed the book here). I also watched several talks by people who talked about the challenges they face managing their distributed systems including the following:
- All Your Base 2014: Laura Thomson, Director of Engineering, Cloud Services Engineering and Operations, Mozilla – Many moving parts: monitoring complex systems
- Velocity Santa Clara 2015: Astrid Atkinson, Director Software Engineering, Google – Engineering for the long game: Managing complexity in distributed systems
- Mountain West Ruby Conference, Paul Hinze, Hashicorp – Primitives of High Availability
- Strange Loop 2015, Camille Fournier – Hopelessness and Confidence in Distributed Systems Design
I’d also like to thank all the members of Mozilla releng/ateam who reviewed my slides and provided feedback before I gave the presentations.
The attendees of the summit attended the same keynote as the LISA attendees. Jez Humble, well known for his Continuous Delivery and Lean Enterprise books provided a keynote on Lean Configuration Management which I really enjoyed. (Older version of slides from another conference, are available here and here.)

In particular, I enjoyed his discussion of the cultural aspects of devops. I especially like that he stated that “You should not have to have planned downtime or people working outside business hours to release”. He also talked a bit about how many of the leaders that are looked up to as visionaries in the tech industry are known for not treating people very well and this is not a good example to set for others who believe this to be the key to their success. For instance, he said something like “what more could Steve Jobs have accomplished had he treated his employees less harshly”.
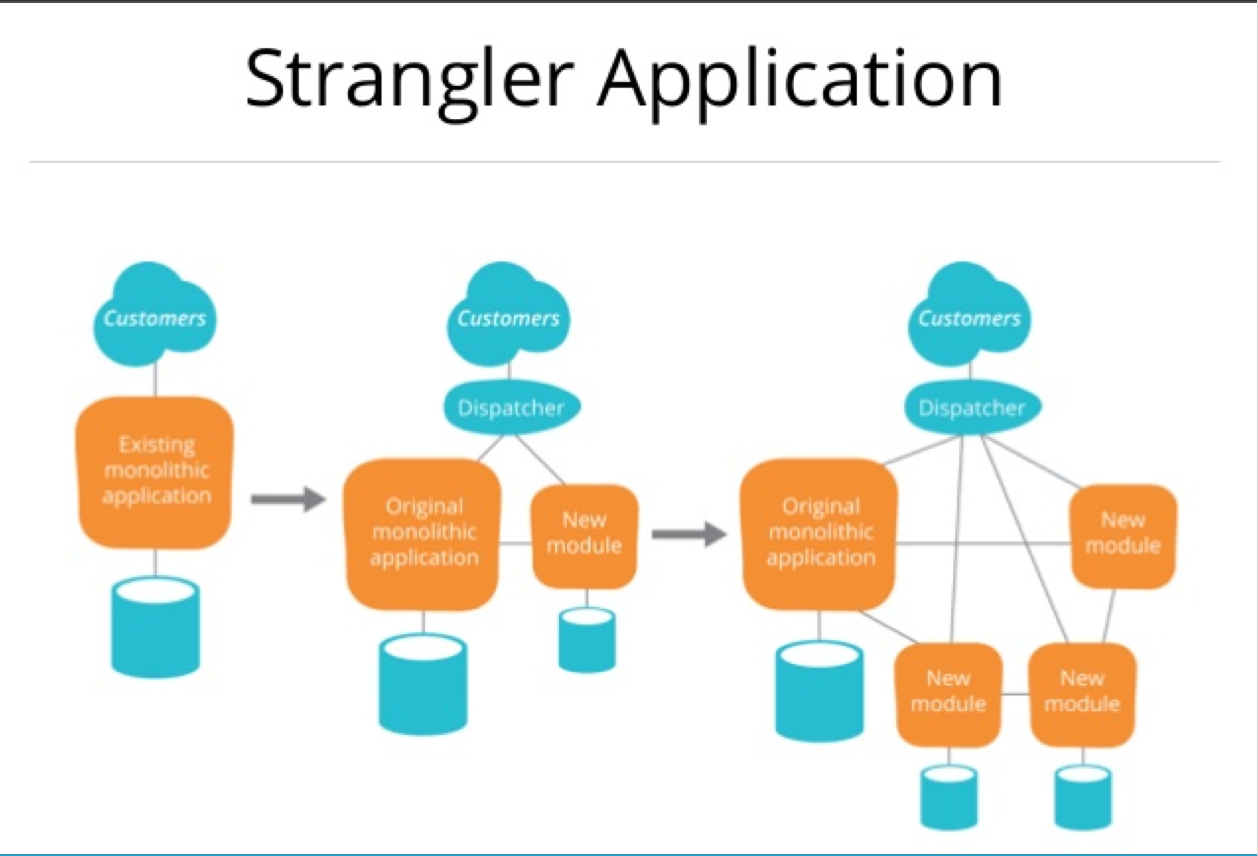
Another concept he discussed which I found interesting was that of the strangler application. When moving from a large monolithic application, the goal is to split out the existing functionality into services until the originally application is left with nothing. Exactly what Mozilla releng is doing as we migrate from Buildbot to taskcluster.
 |
|||
| http://www.slideshare.net/jezhumble/architecting-for-continuous-delivery-54192503 |
At the release engineering summit itself, Lukas Blakk from Pinterest gave a fantastic talk Stop Releasing off Your Laptop—Implementing a Mobile App Release Management Process from Scratch in a Startup or Small Company. This included grumpy cat picture to depict how Lukas thought the rest of the company felt when that a more structured release process was implemented.

Lukas also included a timeline of the tasks that implemented in her first six months working at Pinterest. Very impressive to see the transition!

Another talk I enjoyed was Chaos Patterns – Architecting for Failure in Distributed Systems by Jos Boumans of Krux. (Similar slides from an earlier conference here). He talked about some high profile distributed systems that failed and how chaos engineering can help illuminate these issues before they hit you in production.

For instance, it is impossible for Netflix to model their entire system outside of production given that they consume around one third of nightly downstream bandwidth consumption in the US.
Evan Willey and Dave Liebreich from Pivotal Cloud Foundry gave a talk entitled “Pivotal Cloud Foundry Release Engineering: Moving Integration Upstream Where It Belongs“. I found this talk interesting because they talked about how the built Concourse, a CI system that is more scaleable and natively builds pipelines. Travis and Jenkins are good for small projects but they simply don’t scale for large numbers of commits, platforms to test or complicated pipelines. We followed a similar path that led us to develop Taskcluster.
There were many more great talks, hopefully more slides will be up soon!

0 comments on “USENIX Release Engineering Summit 2015 recap”