Running a large continuous integration farm forces you to deal with many dynamic inputs coupled with capacity constraints. The number of pushes increase. People add more tests. We build and test on a new platform. If the number of machines available remains static, the computing time associated with a single push will increase. You can scale this for platforms that you build and test in the cloud (for us – Linux and Android on emulators), but this costs more money. Adding hardware for other platforms such as Mac and Windows in data centres is also costly and time consuming.
Do we really need to run every test on every commit? If not, which tests should be run? How often do they need to be run in order to catch regressions in a timely manner (i.e. able to bisect where the regression occurred)
Several months ago, jmaher and vaibhav1994, wrote code to analyze the test data and determine the minimum number of tests required to run to identify regressions. They named their software SETA (search for extraneous test automation). They used historical data to determine the minimum set of tests that needed to be run to catch historical regressions. Previously, we coalesced tests on a number of platforms to mitigate too many jobs being queued for too few machines. However, this was not the best way to proceed because it reduced the number of times we ran all tests, not just less useful ones. SETA allows us to run a subset of tests on every commit that historically have caught regressions. We still run all the test suites, but at a specified interval.
 |
| by ©encouragement, Creative Commons by-nc-sa 2.0 |
In the last few weeks, I’ve implemented SETA scheduling in our our buildbot configs to use the data that the analysis that Vaibhav and Joel implemented. Currently, it’s implemented on mozilla-inbound and fx-team branches which in aggregate represent around 19.6% (March 2015 data) of total pushes to the trees. The platforms configured to run fewer tests for both opt and debug are
- MacOSX (10.6, 10.10)
- Windows (XP, 7, 8)
- Ubuntu 12.04 for linux32, linux64 and ASAN x64
- Android 2.3 armv7 API 9
As we gather more SETA data for newer platforms, such as Android 4.3, we can implement SETA scheduling for it as well and reduce our test load. We continue to run the full suite of tests on all platforms other branches other than m-i and fx-team, such as mozilla-central, try, and the beta and release branches. If we did miss a regression by reducing the tests, it would appear on other branches mozilla-central. We will continue to update our configs to incorporate SETA data as it changes.
How does SETA scheduling work?
We specify the tests that we would like to run on a reduced schedule in our buildbot configs. For instance, this specifies that we would like to run these debug tests on every 10th commit or if we reach a timeout of 5400 seconds between tests.
 |
| http://hg.mozilla.org/build/buildbot-configs/file/2d9e77a87dfa/mozilla-tests/config_seta.py#l692 |
Previously, catlee had implemented a scheduling in buildbot that allowed us to coallesce jobs on a certain branch and platform using EveryNthScheduler. However, as it was originally implemented, it didn’t allow us to specify tests to skip, such as mochitest-3 debug on MacOSX 10.10 on mozilla-inbound. It would only allow us to skip all the debug or opt tests for a certain platform and branch.
I modified misc.py to parse the configs and create a dictionary for each test specifying the interval at which the test should be skipped and the timeout interval. If the tests has these parameters specified, it should be scheduled using the EveryNthScheduler instead of the default scheduler.
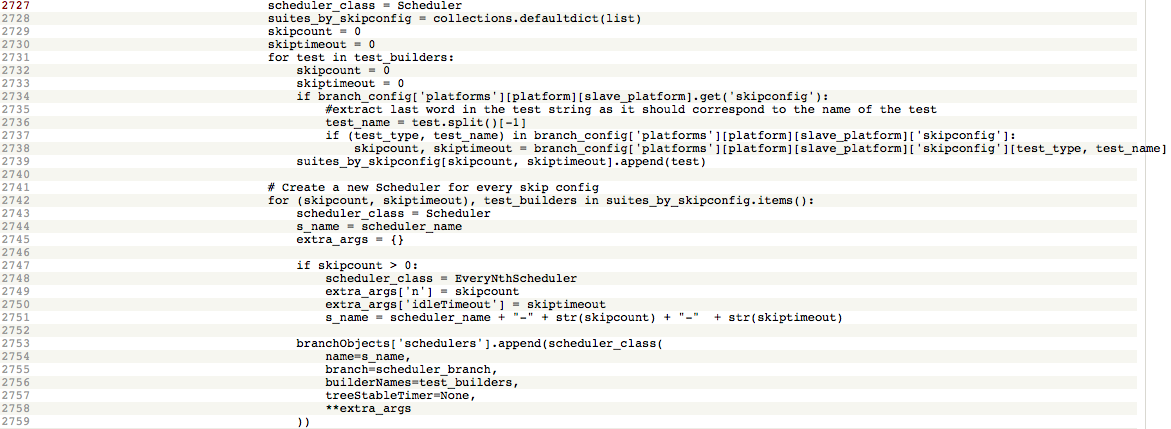 |
| http://hg.mozilla.org/build/buildbotcustom/file/728dc76b5ad0/misc.py#l2727 |
There are still some quirks to work out but I think it is working out well so far. I’ll have some graphs in a future post on how this reduced our test load.
Further reading
Joel Maher: SETA – Search for Extraneous Test Automation

Nice Work Kim! Thanks for implementing SETA in production systems 🙂
LikeLike